Abstract
In this paper we describe Block-o-Matic, a web page segmentation algorithm. It is based on an hybrid approach for scanned document segmentation and visual-based content segmentation. A web page is associated with three structures: the DOM tree, the content structure and the logical structure. The DOM tree represents the HTML elements of a page, the geometric structure organizes the content based on a category and its geometry and finally the logical structure is the result of mapping content structure on the basis of the human-perceptible meaning that conforms the blocks. The segmentation process is divided in three phases: analysis, understanding and reconstruction of a web page. An evaluation method is proposed in order to perform the evaluation of web page segmentations based on a ground truth of 400 pages classified into 16 categories. A set of metrics are presented based on geometric properties of blocks. Satisfactory results are reached when comparing to other algorithms following the same approach
Block-o-Matic Web Page Segmentation Model
We extend the concepts of [4], a model for segmenting digitized document in the optical character
recognition domain, and adapt it to web pages. The content structure is the DOM interface after rendering
a page in a browser. The geometric structure describes a page with respect to the geometric properties of
content elements. The logical structure describes the connections of blocks at a layout level. For example
if a logical block is found at top of page and the next in the bottom, that suggests a vertical layout flow.
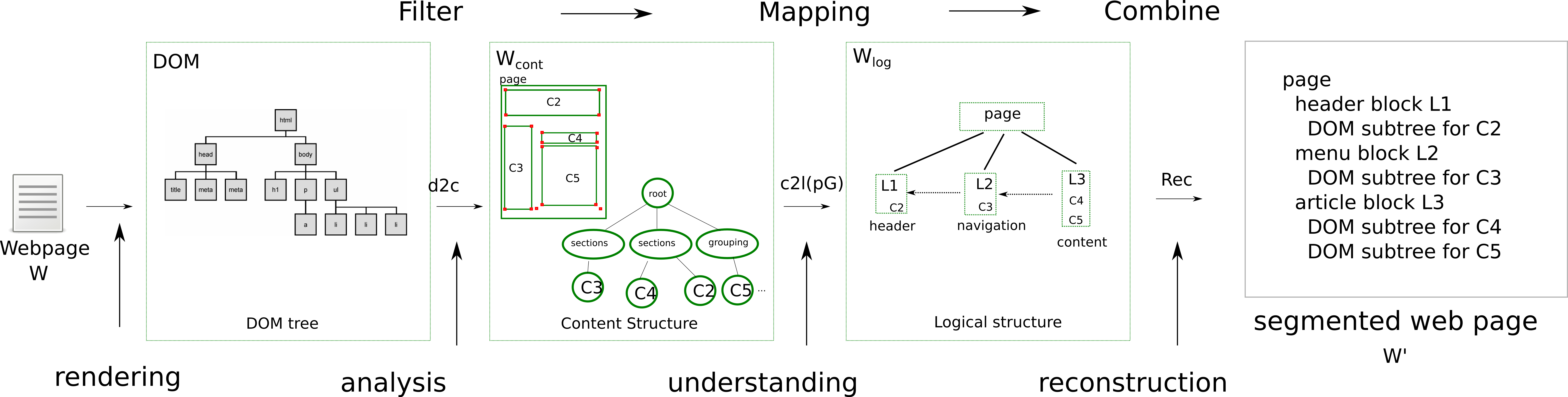
As shown in Figure 1, the segmentation process of a page (W) is divided into three phases: page analysis,
page understanding and page reconstruction. The extraction of the geometric structure (Wgeom) from the
content structure (Wcont) is called web page analysis (c2g function). Mapping the geometric structure
(Wgeom) into a logical structure (Wlog) is called document understanding (g2l function). Rebuilding the
web page from the logic (Wlog), geometric (Wgeo) and content structure (Wcont) is called web page
reconstruction (Rec function) where, W= Rec(W cont , c2g(Wcont), g2l(c2g(Wcont))). The c2g function
′
constructs the geometric structure from the content structure. It organizes the content in function of the
tag as: content, container, content-container or default elements. Additionally, it checks that there are not
overlapping between siblings blocks. The g2l function constructs the logic structure from geometric
structure. It assigns labels to geometrics blocks depending on their position in the web page, the relative
area they occupy and the visual cues of their content elements. The labels are: left, right, top, bottom,
middle or in other case standard. The Rec function builds the page (W') which is the original document
(W) enriched with all structure, into an linear document in a XML-like style.